- Welcome to My Coding Cult.

Recent posts
#11
The pattern V2 / Eden DB Improvements 2
Last post by CultLeader - June 07, 2023, 01:16:27 PMSup guys, it's been a while you lurkers that read my posts but stay silent.
I'm working on Eden platform now, and basis of that is EdenDB, to which I make changes as I need them when working on eden platform. I've made quite a few improvements since last improvements post.
Ability to refer to other element's children through REF FOREIGN CHILD syntax
The need for this arose when I needed for abstractions, like NATS or PostgreSQL instances to specify on that volumes they reside.
Say this is a server table (simplified)
It has volumes as children (simplified)
So say you have server-a with defined volumes
And we need to define a postgres instance of a single cluster (simplified from real schema)
So now we say that we want our foo logical database, with three replicas defined, one will be master with patroni and other replica.
Notice, how we refer to the volume of `server-a` and `server-b` where we want data to reside using `=>` operator, which means child element.
We could nest this arbitrarily deep.
So, by using foreign child syntax syntax we do two things:
1. Specify which server runs the database (parent of the volume)
2. Specify where data on server runs
And, of course, you cannot define non existing elements in EdenDB, so you cannot make a typo of specifying non existing server or volume (unlike in typical yaml hell)
Full gist is here https://gist.github.com/cultleader777/41210e58026a0bec29f7e014945e40b0
Refer to the child element with REF CHILD syntax
Another issue I had working on eden platform is that I wanted to refer to the child element from parent element.
Say, server has multiple network interfaces, how to we specify which interface exposes ssh for us to connect and provision server with?
Say this schema (simplified from original)
So, network interface is a child of server and we can refer to the child from the parent so that we know on which network interface we ssh to every machine.
Also, we can refer to child of arbitrary depth with the `=>` syntax from parent.
As usual, EdenDB fails to compile if existing child elements don't exist.
Full example here https://gist.github.com/cultleader777/d4f26449d2814a30d6b34e55c5d19c76
Detached defaults with DETACHED DEFAULT syntax
I had an issue of working on Eden platform that if default is defined in the database schema then it can't be changed by the user.
This is because eden platform schema resides in one set of files and user defines data in his own set of files.
Say, server has hostname and belongs to tld in the schema file
Now, it would be not nice to specify to which TLD server belongs in the default. Every user of eden platform will have its own domain.
So tld element is DETACHED DEFAULT. It must be defined by the user, and can only ever be defined once. If it is not defined, or defined multiple times it is compiler error.
Full example here https://gist.github.com/cultleader777/3823ccef5c22b4b086c2468ab9e2e89c
And these are the main features I needed to add to EdenDB so far while working on eden platform compiler.
See you later bois!
I'm working on Eden platform now, and basis of that is EdenDB, to which I make changes as I need them when working on eden platform. I've made quite a few improvements since last improvements post.
Ability to refer to other element's children through REF FOREIGN CHILD syntax
The need for this arose when I needed for abstractions, like NATS or PostgreSQL instances to specify on that volumes they reside.
Say this is a server table (simplified)
Code Select
TABLE server {
hostname TEXT PRIMARY KEY,
}It has volumes as children (simplified)
Code Select
TABLE server_volume {
volume_name TEXT PRIMARY KEY CHILD OF server,
mountpoint TEXT,
}So say you have server-a with defined volumes
Code Select
DATA server(hostname) {
server-a WITH server_volume {
pgtest1, '/srv/volumes/pgtest1';
};
server-b WITH server_volume {
pgtest1, '/srv/volumes/pgtest1';
};
}And we need to define a postgres instance of a single cluster (simplified from real schema)
Code Select
TABLE db_deployment {
deployment_name TEXT PRIMARY KEY,
}
TABLE db_deployment_instance {
deployment_id INT PRIMARY KEY CHILD OF db_deployment,
db_server REF FOREIGN CHILD server_volume,
CHECK { deployment_id > 0 },
}So now we say that we want our foo logical database, with three replicas defined, one will be master with patroni and other replica.
Code Select
DATA STRUCT db_deployment [
{
deployment_name: foo WITH db_deployment_instance [
{
deployment_id: 1,
db_server: server-a=>pgtest1,
},
{
deployment_id: 2,
db_server: server-b=>pgtest1,
},
]
}
]Notice, how we refer to the volume of `server-a` and `server-b` where we want data to reside using `=>` operator, which means child element.
We could nest this arbitrarily deep.
So, by using foreign child syntax syntax we do two things:
1. Specify which server runs the database (parent of the volume)
2. Specify where data on server runs
And, of course, you cannot define non existing elements in EdenDB, so you cannot make a typo of specifying non existing server or volume (unlike in typical yaml hell)
Full gist is here https://gist.github.com/cultleader777/41210e58026a0bec29f7e014945e40b0
Refer to the child element with REF CHILD syntax
Another issue I had working on eden platform is that I wanted to refer to the child element from parent element.
Say, server has multiple network interfaces, how to we specify which interface exposes ssh for us to connect and provision server with?
Say this schema (simplified from original)
Code Select
TABLE server {
hostname TEXT PRIMARY KEY,
ssh_interface REF CHILD network_interface,
}
TABLE network {
network_name TEXT PRIMARY KEY,
cidr TEXT,
}
TABLE network_interface {
if_name TEXT PRIMARY KEY CHILD OF server,
if_network REF network,
if_ip TEXT,
if_subnet_mask_cidr INT,
}So, network interface is a child of server and we can refer to the child from the parent so that we know on which network interface we ssh to every machine.
Code Select
DATA STRUCT network [
{
network_name: lan,
cidr: '10.16.0.0/12',
}
]
DATA server(hostname, ssh_interface) {
server-a, eth0 WITH network_interface {
eth0, lan, 10.17.0.10, 24;
};
}Also, we can refer to child of arbitrary depth with the `=>` syntax from parent.
Code Select
TABLE existant_parent {
some_key TEXT PRIMARY KEY,
spec_child REF CHILD existant_child_2,
}
TABLE existant_child {
some_child_key TEXT PRIMARY KEY CHILD OF existant_parent,
}
TABLE existant_child_2 {
some_child_key_2 TEXT PRIMARY KEY CHILD OF existant_child,
}
DATA existant_parent {
outer_val, inner_val=>henloz WITH existant_child {
inner_val WITH existant_child_2 {
henlo
}
}
}As usual, EdenDB fails to compile if existing child elements don't exist.
Full example here https://gist.github.com/cultleader777/d4f26449d2814a30d6b34e55c5d19c76
Detached defaults with DETACHED DEFAULT syntax
I had an issue of working on Eden platform that if default is defined in the database schema then it can't be changed by the user.
This is because eden platform schema resides in one set of files and user defines data in his own set of files.
Say, server has hostname and belongs to tld in the schema file
Code Select
TABLE server {
hostname TEXT PRIMARY KEY,
tld REF tld DETACHED DEFAULT,
fqdn TEXT GENERATED AS { hostname .. "." .. tld },
}
TABLE tld {
domain TEXT PRIMARY KEY,
}Now, it would be not nice to specify to which TLD server belongs in the default. Every user of eden platform will have its own domain.
So tld element is DETACHED DEFAULT. It must be defined by the user, and can only ever be defined once. If it is not defined, or defined multiple times it is compiler error.
Code Select
DEFAULTS {
// defines default for table 'server' and column 'tld'.
// you cannot define defaults for non existing tables
// and column must be marked as detached default
server.tld epl-infra.net,
}
// now we can define data with detached default
DATA STRUCT server {
hostname: server-a
}
DATA tld {
epl-infra.net;
}Full example here https://gist.github.com/cultleader777/3823ccef5c22b4b086c2468ab9e2e89c
And these are the main features I needed to add to EdenDB so far while working on eden platform compiler.
See you later bois!
#12
Development Tips / Testing assembly much?
Last post by CultLeader - March 12, 2023, 06:13:34 PMThis is a long overdue post about assembly. Typically, what we know about assembly language today is that those are low level instructions that fiddle very low level operations with CPU registers, memory, interrupts and etc. In this day and age nobody but compiler writers care about assembly. But even then, if you write a compiler LLVM is available to you where you emit LLVM IR (intermediate representation) instructions and LLVM generates assembly code. It could be x86, arm, PowerPC or any number of supported architectures.
Whatever new assembly language comes out specific for certain chip only very few people of programmer population needs to understand that to port it to yet another platform and all that will be available for the rest of the programmers to use. Today, 99%+ developers don't care about assembly. It is good to understand what it is and how it works, to have conceptual understanding, but to actually fiddle assembly code by hand you either need to have extremely good reason or you're just pretentious or insane.
Why am I talking about this? As I'm developing Eden platform now I need to generate a lot of code. Be it Rust code, shell scripts, nomad job files - all of them are generated now. I don't write these by hand. Most people what is generated in my framework today need to write by hand, care about it, maintain it, fiddle with it, have tests for it.
What I see as inevitable future most of the code people write today will turn into assembly automatically generated without mistakes. No more need to maintain those, you just connect high level table data in eden data language and things will just work. You will not be able to misconfigure service with a bad dns name to connect a certain postgres instance like you can in a garbage yaml hell. You will not be able to operate in DNS names - DNS names to consul services will simply be an irrelevant implementation detail. Part of our generated assembly. What you want to say instead is that deployment of this service speaks to this instance of database which has this and this schema. You don't care about implementation details of DNS.
Today virtually everyone tests this higher level assembly. Is service running? Does it open a port? Does it respond to such and such http request with such and such response?
Of course, compiler writers also have huge test suites that test assembly, certain behaviours of generated code. In the beginning of GCC compiler there were probably lots of bugs, with time they became less and less common to a point where average user encountering a compiler bug is similar to a chance of winning a lottery. Usually, once GCC or rustc runs and compiler successfully emits output, you assume that basic behaviours are correct.
But how can that be? Rustc emit executables with assembly code! You would be crazy to rely on assembly? Since there are high level rules in Rust which are enforced with tests and we now mainly trust that compiler is reasonably correct we trust Rust programs much more than Javascript programs (if you have any sanity) even though both programs are running on the same CPU and they're running same assembly instructions underneath.
With the pattern, most yamls, infrastructure configurations that you'd need to maintain by hand become assembly. Most Rust application code not written by the user becomes assembly. Consul configs become assembly. Nomad configs become assembly. Vault configs become assembly. Postgres configs become assembly. SQL migrations become assembly. NATS configs become assembly. MinIO configs become assembly. Consul policies become assembly. Vault policies become assembly. Nomad job declarations become assembly. Server nix configurations become assembly. Application build scripts become assembly. Nginx configs become assembly.
Another property of assembly is that compiler optimizations change and assembly changes but code doesn't have to. Users don't care. Now at this point for instance I use Nix to provision all servers and have reproducible builds. It is my favorite OS and package manager which will make Eden platform rock solid. But hypothetically, what happens if one day for some reason I will no longer like NixOS as server operating system? I'll just change the assembly code generated for server provisioning and VM images built (user doesn't care and doesn't need to know) to something else in one commit and that's it. Assembly will never be the most important. Assembly is swappable. Assembly is an implementation detail.
And what is the future of assembly? It will become irrelevant. Needless to say there are lots of errors in Eden platform compiler I'm working on during development, but the more and more test written, the more mature this project will become it will be like GCC and Rustc - once compiler runs, tests assumptions/consistencies/port clashes/RAM boundaries/typesafety of applications/db query correctness of your entire infrastructure of 1000 servers and 1000 applications and emits source outputs in a few seconds for your entire infrastructure - you'll just assume things will work and deploy with a smile. Without spinning up thousands of machines for testing. Without spinning up thousands of services.
And what is the future of developers that today need to maintain such assembly? Check job postings for x86 assembly programmers and find out
Have a good day bois!
Whatever new assembly language comes out specific for certain chip only very few people of programmer population needs to understand that to port it to yet another platform and all that will be available for the rest of the programmers to use. Today, 99%+ developers don't care about assembly. It is good to understand what it is and how it works, to have conceptual understanding, but to actually fiddle assembly code by hand you either need to have extremely good reason or you're just pretentious or insane.
Why am I talking about this? As I'm developing Eden platform now I need to generate a lot of code. Be it Rust code, shell scripts, nomad job files - all of them are generated now. I don't write these by hand. Most people what is generated in my framework today need to write by hand, care about it, maintain it, fiddle with it, have tests for it.
What I see as inevitable future most of the code people write today will turn into assembly automatically generated without mistakes. No more need to maintain those, you just connect high level table data in eden data language and things will just work. You will not be able to misconfigure service with a bad dns name to connect a certain postgres instance like you can in a garbage yaml hell. You will not be able to operate in DNS names - DNS names to consul services will simply be an irrelevant implementation detail. Part of our generated assembly. What you want to say instead is that deployment of this service speaks to this instance of database which has this and this schema. You don't care about implementation details of DNS.
Today virtually everyone tests this higher level assembly. Is service running? Does it open a port? Does it respond to such and such http request with such and such response?
Of course, compiler writers also have huge test suites that test assembly, certain behaviours of generated code. In the beginning of GCC compiler there were probably lots of bugs, with time they became less and less common to a point where average user encountering a compiler bug is similar to a chance of winning a lottery. Usually, once GCC or rustc runs and compiler successfully emits output, you assume that basic behaviours are correct.
But how can that be? Rustc emit executables with assembly code! You would be crazy to rely on assembly? Since there are high level rules in Rust which are enforced with tests and we now mainly trust that compiler is reasonably correct we trust Rust programs much more than Javascript programs (if you have any sanity) even though both programs are running on the same CPU and they're running same assembly instructions underneath.
With the pattern, most yamls, infrastructure configurations that you'd need to maintain by hand become assembly. Most Rust application code not written by the user becomes assembly. Consul configs become assembly. Nomad configs become assembly. Vault configs become assembly. Postgres configs become assembly. SQL migrations become assembly. NATS configs become assembly. MinIO configs become assembly. Consul policies become assembly. Vault policies become assembly. Nomad job declarations become assembly. Server nix configurations become assembly. Application build scripts become assembly. Nginx configs become assembly.
Another property of assembly is that compiler optimizations change and assembly changes but code doesn't have to. Users don't care. Now at this point for instance I use Nix to provision all servers and have reproducible builds. It is my favorite OS and package manager which will make Eden platform rock solid. But hypothetically, what happens if one day for some reason I will no longer like NixOS as server operating system? I'll just change the assembly code generated for server provisioning and VM images built (user doesn't care and doesn't need to know) to something else in one commit and that's it. Assembly will never be the most important. Assembly is swappable. Assembly is an implementation detail.
And what is the future of assembly? It will become irrelevant. Needless to say there are lots of errors in Eden platform compiler I'm working on during development, but the more and more test written, the more mature this project will become it will be like GCC and Rustc - once compiler runs, tests assumptions/consistencies/port clashes/RAM boundaries/typesafety of applications/db query correctness of your entire infrastructure of 1000 servers and 1000 applications and emits source outputs in a few seconds for your entire infrastructure - you'll just assume things will work and deploy with a smile. Without spinning up thousands of machines for testing. Without spinning up thousands of services.
And what is the future of developers that today need to maintain such assembly? Check job postings for x86 assembly programmers and find out
Have a good day bois!
#13
Natural Philosophy / "... there should be time no l...
Last post by CultLeader - January 04, 2023, 05:22:49 PMAnd the angel which I saw stand upon the sea and upon the earth lifted up his hand to heaven, And sware by him that liveth for ever and ever, who created heaven, and the things that therein are, and the earth, and the things that therein are, and the sea, and the things which are therein, that there should be time no longer: - Revelation 10:5-6
I'm at the point where I'm developing eden platform, which will be the first open source version of the pattern. I'll likely be able to release the early achy breaky version as a proof of concept in half a year.
I came across an interesting thing when developing this project. Now my infrastructure and apps are all data. And I picked nomad to be the scheduler, vault storage for secrets (I run full hashicorp stack and I think kubernetes is cancer). Same thing that happened with Java and C# happened with Kubernetes and Nomad. Java is a complete and utter garbage of a language, C# had the hindsight of all the mistakes Java made and used it to create paid but much more superior product. Kubernetes also is the first Java, yaml hell and Hashicorp used its bad practices to create much better and pleasant orchestrator to work with.
When I was developing the pattern of my infrastructure I had a very specific problem I needed to solve.
Nomad application needs to access a secret that depends on database existing. If you run infrastructure the first time, neither database nor application exists. We're still in the planning stage.
So, it would be very complex if first we deploy database, then generate passwords and only then put password to vault and application can access it. Nasty chain of dependencies.
Instead what I did, logical plan of all the applications is built in memory. Application states that it will want to connect to the database X. Then code is generated that secret simply exists there in the nomad .hcl job file. Then also code is generated to provision that secret, generate random 42 character string and put it in vault. Code is also generated to provision that database user to access it.
What typically happens in companies, you need access to the database. All things happen in chronological order:
1. Database is provisioned
2. User credentials are generated
3. Credentials are provided to the user
4. He uses the database
What, I did instead, everything is happening at once. Before even application is deployed it knows it will need so and so secret to access it. Before database is deployed it knows it will need so and so user for application which doesn't even exist yet. This way, with the pattern, I see everything at once. I see all the applications before they even exist. I see all the databases before they are even provisioned, and they perfectly work together the first time.
This is a true godlike power, knowing and having all information at once in one place in this small infrastructure world I am creating.
Now all these times where God predicted something will happen in the bible, why God has infinite power or how God can nudge anything to happen in his direction make perfect sense. God sees everything at once, there is no before and after in the eyes of the LORD.
But, beloved, be not ignorant of this one thing, that one day is with the Lord as a thousand years, and a thousand years as one day. - 2 Peter 3:8
LORD has the higher ways we cannot understand:
For my thoughts are not your thoughts, neither are your ways my ways, saith the LORD. For as the heavens are higher than the earth, so are my ways higher than your ways, and my thoughts than your thoughts. - Isaiah 55:8-9
God sees everything from above we can't see:
And he said unto them, Ye are from beneath; I am from above: ye are of this world; I am not of this world. - John 8:23
We, as flesh, think only of one dimensional world. What we see locally is what we react to, can see and touch. What we perceive as time is simply our restricted vision which is disconnected from the entire view of the universe that God has. One day I will also see as God sees, know as I am known of God.
For now we see through a glass, darkly; but then face to face: now I know in part; but then shall I know even as also I am known. - 1 Corinthians 13:12
So, like I mentioned, the pattern framework that I'm building will be the first of its kind. And as I mentioned, any design worth anything at all will have to inevitably resemble divine patterns found in heaven. This framework will have unlimited power within its own respective universe.
- We will know what ports are used for what service before infrastructure is even deployed. Port conflicts will be impossible, and we won't need to spin up machines to test this.
- We will know that too many services are scheduled on one node with memory requirements that go above bounds of machine.
- We will know that 100 applications will perfectly interact with binary queues with perfect typesafety before anything is ever deployed.
- We will know that queries of every application work and hit indexes before anything is deployed.
No more spinning up cluster of machines to see if things work together, all of that will become automatically generated assembly perfectly interacting with each other.
I'm very excited about the future of eden platform, and can't wait to release this project to the world. There is nothing like this.
Happy new year by the way!
I'm at the point where I'm developing eden platform, which will be the first open source version of the pattern. I'll likely be able to release the early achy breaky version as a proof of concept in half a year.
I came across an interesting thing when developing this project. Now my infrastructure and apps are all data. And I picked nomad to be the scheduler, vault storage for secrets (I run full hashicorp stack and I think kubernetes is cancer). Same thing that happened with Java and C# happened with Kubernetes and Nomad. Java is a complete and utter garbage of a language, C# had the hindsight of all the mistakes Java made and used it to create paid but much more superior product. Kubernetes also is the first Java, yaml hell and Hashicorp used its bad practices to create much better and pleasant orchestrator to work with.
When I was developing the pattern of my infrastructure I had a very specific problem I needed to solve.
Nomad application needs to access a secret that depends on database existing. If you run infrastructure the first time, neither database nor application exists. We're still in the planning stage.
So, it would be very complex if first we deploy database, then generate passwords and only then put password to vault and application can access it. Nasty chain of dependencies.
Instead what I did, logical plan of all the applications is built in memory. Application states that it will want to connect to the database X. Then code is generated that secret simply exists there in the nomad .hcl job file. Then also code is generated to provision that secret, generate random 42 character string and put it in vault. Code is also generated to provision that database user to access it.
What typically happens in companies, you need access to the database. All things happen in chronological order:
1. Database is provisioned
2. User credentials are generated
3. Credentials are provided to the user
4. He uses the database
What, I did instead, everything is happening at once. Before even application is deployed it knows it will need so and so secret to access it. Before database is deployed it knows it will need so and so user for application which doesn't even exist yet. This way, with the pattern, I see everything at once. I see all the applications before they even exist. I see all the databases before they are even provisioned, and they perfectly work together the first time.
This is a true godlike power, knowing and having all information at once in one place in this small infrastructure world I am creating.
Now all these times where God predicted something will happen in the bible, why God has infinite power or how God can nudge anything to happen in his direction make perfect sense. God sees everything at once, there is no before and after in the eyes of the LORD.
But, beloved, be not ignorant of this one thing, that one day is with the Lord as a thousand years, and a thousand years as one day. - 2 Peter 3:8
LORD has the higher ways we cannot understand:
For my thoughts are not your thoughts, neither are your ways my ways, saith the LORD. For as the heavens are higher than the earth, so are my ways higher than your ways, and my thoughts than your thoughts. - Isaiah 55:8-9
God sees everything from above we can't see:
And he said unto them, Ye are from beneath; I am from above: ye are of this world; I am not of this world. - John 8:23
We, as flesh, think only of one dimensional world. What we see locally is what we react to, can see and touch. What we perceive as time is simply our restricted vision which is disconnected from the entire view of the universe that God has. One day I will also see as God sees, know as I am known of God.
For now we see through a glass, darkly; but then face to face: now I know in part; but then shall I know even as also I am known. - 1 Corinthians 13:12
So, like I mentioned, the pattern framework that I'm building will be the first of its kind. And as I mentioned, any design worth anything at all will have to inevitably resemble divine patterns found in heaven. This framework will have unlimited power within its own respective universe.
- We will know what ports are used for what service before infrastructure is even deployed. Port conflicts will be impossible, and we won't need to spin up machines to test this.
- We will know that too many services are scheduled on one node with memory requirements that go above bounds of machine.
- We will know that 100 applications will perfectly interact with binary queues with perfect typesafety before anything is ever deployed.
- We will know that queries of every application work and hit indexes before anything is deployed.
No more spinning up cluster of machines to see if things work together, all of that will become automatically generated assembly perfectly interacting with each other.
I'm very excited about the future of eden platform, and can't wait to release this project to the world. There is nothing like this.
Happy new year by the way!
#14
Development Tips / The infinite whac-a-mole
Last post by CultLeader - October 01, 2022, 11:24:46 AMToday, there are two ways to develop software under the heaven. Namely:
- A game of infinite whac-a-mole (virtually all of the software development today)
- Quadractic improvements (the pattern)
To understand today's game of infinite whac-a-mole let's create a matrix, rows are applications and columns are features
This matrix is of many applications in rows interacting with the same features. There can be very many features and very many apps. In our imaginary matrix we have 1000 features and we have a thousand apps.
Today what happens in big companies, developers are being hired to whack moles in this table for some apps or features. Developers are being thrown to at this table, for instance, to build load balancers for the apps, to build persistence for the apps, or just develop apps and talk with infra if you need some components done.
Basically, developers can cover only small parts of this table. Imagine, performance team is created and they need to expose metrics for a certain application to collect them. They need to go through specific apps and mark only one square of this table as completed. Same with many other features. Sometimes improvements are quadratic, for instance, in kubernetes cluster logging is built once and all apps logs go to one place. Or, for instance, NixOS is a quadratic improvement because it gives reproducible builds if all the apps use it. But anyway, whenever your task is "go to such and such an app and fix this bug about such and such feature not working" - you're whacking one x on this infinite table. You're doing monkey's work putting out fires forever. For instance, some database query is not tested, returns null somewhere and system doesn't work and that's extra work. Or some golang garbage app leaks memory due to having very weak abstractions (don't forget to manually put your precious defer everywhere, faggots! I'll just use rust and don't do that at all and resources will be reclaimed automatically).
With the pattern we focus only on quadratic improvements. We do things once, and cover them for every app. We prevent entire class of bugs because we use only rust and ocaml. No nil pointer exceptions and no defer garbage like in golang. We cover database access for the entire column for every single app in the infrastructure - we know that queries that apps use are valid, backwards compatible and that hit indexes (no seq scans in production). We write once to check queries that apps use and we know all applications in our infrastructure will have the same property of only using valid queries that hit indexes. We write once prometheus exports as data for every app, then code is generated for that app to increment specific global variable about a metric and it will always work the first time for every app under the sun (if the prometheus variable is not used by the app that's a compiler warning as error and cannot end up in production). We have backwards compatible structs for every app and application can only use typesafe structures to access the queues and it will always work.
With the pattern, you typically do things once per feature column and all applications benefit. How many entries this matrix has, a million? Say it is million units of work. If one developer on average does 1000 units of work in a given year then you'd need 1000 developers to maintain all of this table. However, if you go quadratic, use the pattern, and you fill column for every application at once, that's only 1000 units of work and can be done by one developer in a reasonable amount of time. You see, when I said the pattern allows one person to do the work of 1000 developers I wasn't kidding. Square root of one million is one thousand, no? How much less work you'd have if you didn't have to test every application as thoroughly with integration tests and spinning up of machines? Knowing they interact with the rest of the system with perfect typesafety? Knowing your performance counters are automatically incremented when interacting with database or with queue? Counting every byte sent to queue or database? Knowing you automatically have monitoring of a thread for 100% of CPU usage of that thread? Knowing you have preplanned autoscaling policies in place ready?
That's why I don't consider big companies seriously. You'd think that people in google are supposed to be smart but golang is an utter half-assed trash. And that is easy to explain - they have thousands of developers to play infinite whac-a-mole. Tiny brain of an average googler never had to think about how to accomplish most work with the least hands. Most people who work there are a tiny cog in a wheel that do very specific small task and that are easily replaceable. Of course, just like in weight lifting, if you go into a work every day and only do ten sets with minimal weight your muscle won't grow. The only way to grow muscle is pushing it to the limit, doing few reps until failure with heavy weights you can barely lift.
The only way to reach infinite productivity is to be in a position where you're alone and you need to perform infinite amount of work. Like God is and God alone created everything:
Fear ye not, neither be afraid: have not I told thee from that time, and have declared it? ye are even my witnesses. Is there a God beside me? yea, there is no God; I know not any. - Isaiah 44:8
God of the bible doesn't know any gods beside him. Nobody helped him. Yet he alone had to create all the heaven and the earth and the sea and all that in them is. Leftist faggots, whenever they have their pathetic small work of being a kubernetes admin, they dismiss the ideas that replace them. Everything is relative! There's no panacea! Everything has pro's and con's! Yaml's are fine! Do more integration tests! We yaml maintaining monkeys are needed, pay us our salary! We need performance team! Ruby is fine, just write more tests and have more coverage! Many divided github repositories are fine, just do more integration tests! Hire more QA testers! When with the pattern when you go quadractic you can easily fire 90% of them and do things much faster.
Eventually 99% of developers will be easily replaceable and fireable, most work done today replaced with quadratic systems of the pattern. There will be only a need for a masculine plane developers that makes all things work together and understand how all things work through and through. Not some monkey who knows specific kubernetes yamls (which in the future will all be generated without mistake anyway with the pattern) and isn't capable of anything else. The developer that will be most useful in the future will be someone who is in God's image - knowing of how everything works in the system together. The rest will be people working in feminine plane who use the system in a typesafe way, filling in the blanks in the pattern system and hence will get much lower salaries due to much lower understanding requirements to do their job. Like in customer support where the vast majority of employees are women.
Just like when God created this earth - a huge framework where out of the box there is food, water, oxygen, sun for heat and energy, fertile soil, useful animals already and etc. - we just needed to use them without necessarily knowing intricate details of how everything works together.
Have a good day, bois!
- A game of infinite whac-a-mole (virtually all of the software development today)
- Quadractic improvements (the pattern)
To understand today's game of infinite whac-a-mole let's create a matrix, rows are applications and columns are features
Code Select
| application | monitoring | database access | queues | logging | proxying | load balancing | .. | feature 1000th |
|-------------+------------+-----------------+--------+---------+----------+----------------+----+----------------|
| app 1 | | | | | | | | |
| app 2 | | | | | | | | |
| app 3 | | | | | | | | |
| ... | | | | | | | | |
| app 1000th | | | | | | | | |
This matrix is of many applications in rows interacting with the same features. There can be very many features and very many apps. In our imaginary matrix we have 1000 features and we have a thousand apps.
Today what happens in big companies, developers are being hired to whack moles in this table for some apps or features. Developers are being thrown to at this table, for instance, to build load balancers for the apps, to build persistence for the apps, or just develop apps and talk with infra if you need some components done.
Basically, developers can cover only small parts of this table. Imagine, performance team is created and they need to expose metrics for a certain application to collect them. They need to go through specific apps and mark only one square of this table as completed. Same with many other features. Sometimes improvements are quadratic, for instance, in kubernetes cluster logging is built once and all apps logs go to one place. Or, for instance, NixOS is a quadratic improvement because it gives reproducible builds if all the apps use it. But anyway, whenever your task is "go to such and such an app and fix this bug about such and such feature not working" - you're whacking one x on this infinite table. You're doing monkey's work putting out fires forever. For instance, some database query is not tested, returns null somewhere and system doesn't work and that's extra work. Or some golang garbage app leaks memory due to having very weak abstractions (don't forget to manually put your precious defer everywhere, faggots! I'll just use rust and don't do that at all and resources will be reclaimed automatically).
With the pattern we focus only on quadratic improvements. We do things once, and cover them for every app. We prevent entire class of bugs because we use only rust and ocaml. No nil pointer exceptions and no defer garbage like in golang. We cover database access for the entire column for every single app in the infrastructure - we know that queries that apps use are valid, backwards compatible and that hit indexes (no seq scans in production). We write once to check queries that apps use and we know all applications in our infrastructure will have the same property of only using valid queries that hit indexes. We write once prometheus exports as data for every app, then code is generated for that app to increment specific global variable about a metric and it will always work the first time for every app under the sun (if the prometheus variable is not used by the app that's a compiler warning as error and cannot end up in production). We have backwards compatible structs for every app and application can only use typesafe structures to access the queues and it will always work.
With the pattern, you typically do things once per feature column and all applications benefit. How many entries this matrix has, a million? Say it is million units of work. If one developer on average does 1000 units of work in a given year then you'd need 1000 developers to maintain all of this table. However, if you go quadratic, use the pattern, and you fill column for every application at once, that's only 1000 units of work and can be done by one developer in a reasonable amount of time. You see, when I said the pattern allows one person to do the work of 1000 developers I wasn't kidding. Square root of one million is one thousand, no? How much less work you'd have if you didn't have to test every application as thoroughly with integration tests and spinning up of machines? Knowing they interact with the rest of the system with perfect typesafety? Knowing your performance counters are automatically incremented when interacting with database or with queue? Counting every byte sent to queue or database? Knowing you automatically have monitoring of a thread for 100% of CPU usage of that thread? Knowing you have preplanned autoscaling policies in place ready?
That's why I don't consider big companies seriously. You'd think that people in google are supposed to be smart but golang is an utter half-assed trash. And that is easy to explain - they have thousands of developers to play infinite whac-a-mole. Tiny brain of an average googler never had to think about how to accomplish most work with the least hands. Most people who work there are a tiny cog in a wheel that do very specific small task and that are easily replaceable. Of course, just like in weight lifting, if you go into a work every day and only do ten sets with minimal weight your muscle won't grow. The only way to grow muscle is pushing it to the limit, doing few reps until failure with heavy weights you can barely lift.
The only way to reach infinite productivity is to be in a position where you're alone and you need to perform infinite amount of work. Like God is and God alone created everything:
Fear ye not, neither be afraid: have not I told thee from that time, and have declared it? ye are even my witnesses. Is there a God beside me? yea, there is no God; I know not any. - Isaiah 44:8
God of the bible doesn't know any gods beside him. Nobody helped him. Yet he alone had to create all the heaven and the earth and the sea and all that in them is. Leftist faggots, whenever they have their pathetic small work of being a kubernetes admin, they dismiss the ideas that replace them. Everything is relative! There's no panacea! Everything has pro's and con's! Yaml's are fine! Do more integration tests! We yaml maintaining monkeys are needed, pay us our salary! We need performance team! Ruby is fine, just write more tests and have more coverage! Many divided github repositories are fine, just do more integration tests! Hire more QA testers! When with the pattern when you go quadractic you can easily fire 90% of them and do things much faster.
Eventually 99% of developers will be easily replaceable and fireable, most work done today replaced with quadratic systems of the pattern. There will be only a need for a masculine plane developers that makes all things work together and understand how all things work through and through. Not some monkey who knows specific kubernetes yamls (which in the future will all be generated without mistake anyway with the pattern) and isn't capable of anything else. The developer that will be most useful in the future will be someone who is in God's image - knowing of how everything works in the system together. The rest will be people working in feminine plane who use the system in a typesafe way, filling in the blanks in the pattern system and hence will get much lower salaries due to much lower understanding requirements to do their job. Like in customer support where the vast majority of employees are women.
Just like when God created this earth - a huge framework where out of the box there is food, water, oxygen, sun for heat and energy, fertile soil, useful animals already and etc. - we just needed to use them without necessarily knowing intricate details of how everything works together.
Have a good day, bois!
#15
The pattern V2 / Eden DB Improvements 1
Last post by CultLeader - August 15, 2022, 07:59:30 AMSup bois, some improvements were made to the EdenDB to allow it to be much more flexible than standard SQL.
Basically, I was experimenting of how to represent domain problems as data, and I had to start with the servers.
Code Select
TABLE server {
hostname TEXT PRIMARY KEY,
}
Then I wanted to solve the infinite problem - how to check that no server has duplicate ports.
But ports are used by many abstractions, say, docker containers, systemd services and so on.
How do we ensure that different abstractions that use ports do not take duplicate port on the same server?
I kinda fell little short.
Let's see how reserved port table looks.
Code Select
TABLE reserved_port {
number INT PRIMARY KEY CHILD OF server,
}
Port is child of server. Now, say, we have docker containers. How do we refer to the reserved ports?
Before improvements shown in this post this is invalid
Code Select
TABLE docker_container {
name TEXT PRIMARY KEY CHILD OF server,
}
TABLE docker_container_port {
port_name TEXT PRIMARY KEY CHILD OF docker_container,
reserved_port REF reserved_port,
}
We couldn't refer to a reserved port because there's no unique key.
But then I thought, wait a minute, if both elements are ancestors of server, why the uniqueness context for port must be global?
If you think about it, the uniqueness context for such table that is child of anything ought to be the common ancestor. And if we imagine that every tables common ancestor is imaginary root table, then it makes perfect sense - everything is unique in the root table context.
This is how current topology looks visualized:
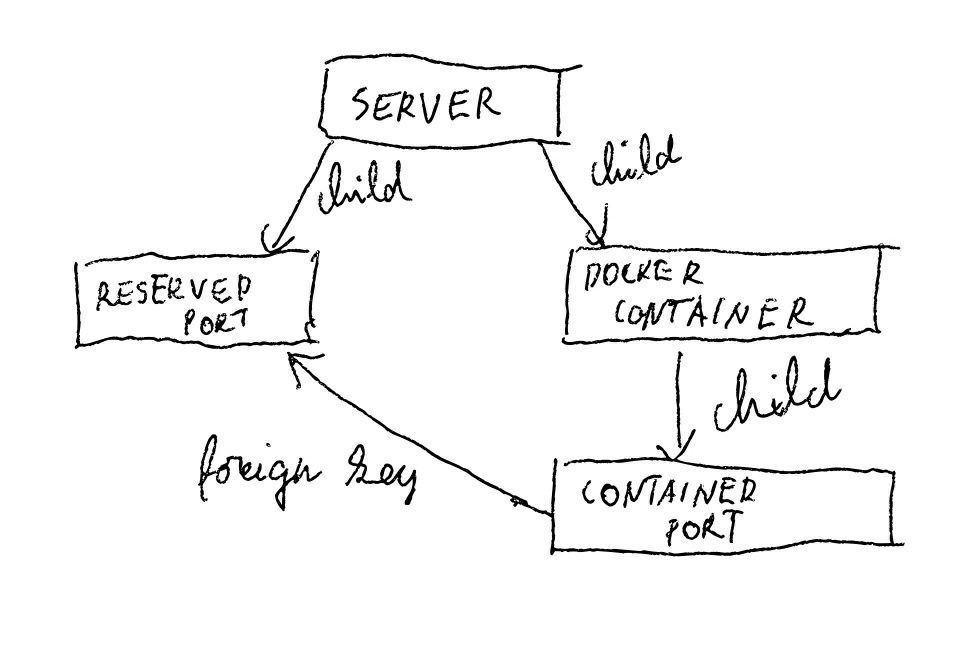
So, basically, the concept of a foreign key would be much more useful, if REF to another table would refer to the uniqueness context of the parent of the referred table.
So, having many different abstractions we can reserve ports in the single server so they would never clash and we find out about this before production when some systemd service can't start!
Let's define some fictional docker container running on some server with reserved port:
Code Select
DATA server {
epyc-1
}
DATA STRUCT docker_container {
hostname: epyc-1,
name: postgres
WITH docker_container_port {
port_name: main_port,
reserved_port: 5432
}
}
This so far does not work because of an error that reserved port does not exist in server:
Code Select
NonExistingForeignKey { table_with_foreign_key: "docker_container_port", foreign_key_column: "reserved_port", referred_table: "reserved_port", referred_table_column: "number", key_value: "5432" }
We must reserve the port also.
Code Select
DATA reserved_port {
epyc-1, 5432
}
Now stuff compiles. And we cannot add more `reserved_port` with same value or stuff fails, if we copy reserved_port statement once again, boom:
Code Select
FoundDuplicateChildPrimaryKeySet { table_name: "reserved_port", columns: "(hostname, number)", duplicate_values: "(epyc-1, 5432)" }
However, there's an issue that we would need to repeat reserved_port statement along with defining docker containers. Which leads to another improvement done to EdenDB: add rows with lua.
Basically, instead of defining this data by hand, now we can run lua code and insert to any table we want:
Code Select
INCLUDE LUA {
data('reserved_port', { hostname = 'epyc-1', number = 5432 })
}
And, of course, you must refer existing table and you must only define existing columns or compiler yiels at you.
`data` internal edendb function implementation is so trivial that I'll simply post it here:
Code Select
__do_not_refer_to_this_internal_value_in_your_code_dumbo__ = {}
function data(targetTable, newRow)
local queue = __do_not_refer_to_this_internal_value_in_your_code_dumbo__
if queue[targetTable] == nil then
queue[targetTable] = {}
end
-- we simply accumulate values to insert in lua runtime and then process
-- them in one go in rust
table.insert(queue[targetTable], newRow)
end
We simply have a global queue of rows to be inserted from lua and we iterate this map and insert data defined in lua in one go.
So, now, to avoid repetition we can simply define lua function that defines a docker container by inserting into all appropriate places we want:
Code Select
INCLUDE LUA {
function docker_container(hostname, containerName, portName, portValue)
data('docker_container', {
hostname = hostname,
name = containerName,
})
data('docker_container_port', {
hostname = hostname,
name = containerName,
port_name = portName,
reserved_port = portValue
})
data('reserved_port', {
hostname = hostname,
number = portValue,
})
end
}
Data order doesn't matter, all checks are processed only once all data has been inserted into tables.
And we just call this function once in lua of defining postgres container, while encapsulating complexity, and deleting previous data definitions for this docker container:
Code Select
INCLUDE LUA {
docker_container('epyc-1', 'postgres', 'main_port', 5432)
}
Of course, I wrote a terse funtion as an example, in production likely there will be named map arguments with many default parameters provided internally in the function to make this more practical.
To be more practical, we include lua files for library stuff (this feature already existed):
Code Select
INCLUDE LUA "lib.lua"
Full working gist can be found here https://gist.github.com/cultleader777/175fb37cb2ce1c9cb317ce2d187a926b
So, these are the two recent improvements that gave eden data language quite more power:
1. allowing foreign keys to refer to other child rows in the entity
2. defining data from lua, you can script anything you possibly want
Good day bois.
#16
The pattern V2 / Eden Data Language: introducti...
Last post by CultLeader - August 01, 2022, 05:35:15 PMhttps://github.com/cultleader777/EdenDB
So, this is a brand new language that focuses on... Simply defining data. Like YAML, but not garbage, typesafe, no nulls or NaNs, with schemas and blazing fast to query. Compiles and emits outputs in milliseconds and relentlessly checks logical errors to disallow funny stuff in production.
Let's have a taste, shall we?
Say we have a table of servers
They can have disks, as children
Looks similar to SQL, who needs another SQL dialect? Ok, let's see how we can define server with disks, in three ways:
As you can see, much less verbose and straight to the point as opposed to
There is no concept of insert statement because data is immutable.
Let's add some disks 1TB and 1.5TB disks that are children to server
The column order
This is rather verbose of adding separate rows for every server we want into separate place. Also, we redundantly repeat disk hostname.
Could we have everything in one place, so that it would look structured?
We can, with the WITH statement, let's define the same but in more concise way:
And here's the magic. We can define child or foreign key elements with WITH keyword and key of parent element will travel to children. There can be many levels of children and WITH statement can also be nested arbitrarily deep. There's a bunch of logic to check for errors, you can read test suite.
But long story short, this is not the garbage of `.yaml` where you can write anything we want, then you run tests and pray it will work. All fields are checked of being appropriate type, all fields must be defined, no null values are allowed and all the stuff like that is checked. Consider this typesafety as strong as defining struct in Rust or OCaml and knowing it will never have nulls or funny values.
Also, there's another variation of `WITH` so that our elements begin to look completely like traditional nested maps in programming languages, this statement is also equivalent:
So, we represented the same data in three ways and all this will end up as columns for us to analyze.
Aight, what can we do, how about our data correctness?
We can write SQL (thanks embedded sqlite) to prove anything we want about our data with good ol' SQL.
Let's write a proof that we don't have smaller disks than 10GB.
How do we prove we have nothing of certain kind? By searching for it and finding none. This is important, because if this proof in eden data language fails, it will return rowid of the offending rows which can be printed out to user so he could figure out where to fix his data.
Okay, SQL proof might be a little overkill on this, we have also column checks (thanks embedded lua).
Here's how we could have defined the disks table to have same thing checked with lua:
Also, lets have a lua computed column for size in megabytes of the disk:
Lua snippet must return an integer or compiler yells at you. No nulls are ever allowed to be returned by computed columns either.
But wait, there's more!
Datalog is the most elegant query language I've ever seen my life. But for datalog to be of any practical use at all, we cannot have any queries that refer to non existing facts or rules. I've found a decent datalog implementation for rust https://crates.io/crates/asdi , unfortunately, it does not support `NOT` statements or arithmetic operators of less, more and etc. So, I'll show two datalog proofs against our data, one that works today (even though it is meaningless) and one that would be practical and would work as soon as asdi starts supporting less than operator.
As you can see, our computed column size_mb is available in datalog to query.
But wait, there's more! EdenDB exports typesafe Rust or OCaml code to work with. Basically, once everything is verified we can generate typesafe code and analyze our data with a programming language if we really want to perform some super advanced analysis of our data.
Let's run this:
On my computer this compilation literally took 6 milliseconds (thanks rust!). It should never appear in a profiler in a compilation process, unlike most compilers these days...
Let's see the rust source that got compiled!
To get rows from table we can only get them through TableRowPointer special type for every single table. This type is basically wrapped usize and is a zero cost abstraction in rust. But, if you were to use raw usize you'd have a chance of passing TableRowPointerDisks to the server table, which is impossible here. TableRowPointer is just an index to arrays of our column or row stored data.
There are only two ways we can get TableRowPointer for every table:
1. We do a seq scan through entire table to get valid pointers
2. Pointers to other tables may exist as a column in a table. For instance, we can get generated .parent from disk row, or children_disks column generated for server table
Database is immutable and can never be mutated. User in rust can only ever get immutable references to columns. Meaning, you can run thousands of proofs in parallel against this data without ever worrying about locks/consistency and etc. Once your database is compiled it is a done deal and it will never change.
So we don't have nasty garbage in our api like, does this row exist? I better return an Option! No, if you ever have a TableRowPointer value it will ALWAYS point to a valid row in a one and only unique table. You can clone that pointer for free, store it in million other places and it will always point to the same column in the same table.
Of course, we should prefer using column api for performance, getting entire table row is added for convenience.
Deserialization assumes certain order in the include_bytes!() binary data and does not maintain data about tables already read/etc - we just assume that we wrote things in certain order in edendb and read them back in the same order. Also, binary data for rust is compressed with lz4 compression.
OCaml api is analogous and gives the same guarantees. Immutable data, separate types for table pointers for each table and so on.
Okay, let's do something practical with this, let's prove that no intel disks are never next to some cheap crucial disks to not ever humiliate them like that!
We'll change schema a little bit, let's add, what is effectively, a disk manufacturer enum:
Also, let's add our disks to contain the make column with this data:
Now our data is redefined with disk manufacturer:
So, how would the rust source look to prove that no intel disk is next to a cheap crucial disk? There ya go, full main.rs file:
Do you miss endless matching of some/none options to check if some value by key exists in the table or endless unwraps? Me neither. We just get all the values directly because we know they will always be valid given we have table row pointers which can only ever be valid.
Full example project can be found here
So, basically, let's recap all the high level tools EdenDB gives to be successful working and building assumptions about your data:
1. SQL proofs
2. Lua checks/computed columns
3. Datalog (so far meh)
4. Analyze data directly in Rust or OCaml if all else fails
Basically, 4 ways to analyze the same data from four different languages and all data is statically typed and super fast/column based in the end.
Also, there are these features I didn't mention:
- include multiple files syntax
- include lua files
- unique constraints
- sqlite materialized views
- countless checks for correctness (check enum count in errors.rs file)
To see all features of EdenDB check out the tests, because I usually try to test every feature thoroughly.
And more will be added as I see fit.
What can I more say? Having such foundations, time to build the most productive open source web development platform of all time 😜
So, this is a brand new language that focuses on... Simply defining data. Like YAML, but not garbage, typesafe, no nulls or NaNs, with schemas and blazing fast to query. Compiles and emits outputs in milliseconds and relentlessly checks logical errors to disallow funny stuff in production.
Let's have a taste, shall we?
Say we have a table of servers
Code Select
TABLE server {
hostname TEXT PRIMARY KEY,
ram_mb INT,
}
They can have disks, as children
Code Select
TABLE disks {
disk_id TEXT PRIMARY KEY CHILD OF server,
size_bytes INT,
}
Looks similar to SQL, who needs another SQL dialect? Ok, let's see how we can define server with disks, in three ways:
Code Select
DATA server {
my-precious-epyc1, 4096;
my-precious-epyc2, 8192;
}
As you can see, much less verbose and straight to the point as opposed to
Code Select
INSERT INTO ... statement.There is no concept of insert statement because data is immutable.
Let's add some disks 1TB and 1.5TB disks that are children to server
Code Select
DATA disks(hostname, disk_id, size_bytes) {
my-precious-epyc1, root-disk, 1000000000000;
my-precious-epyc2, root-disk, 1500000000000;
}
The column order
Code Select
(hostname, disk_id, size_bytes) is explicit here but as we've seen with server default tuple order is assumed if ommited.This is rather verbose of adding separate rows for every server we want into separate place. Also, we redundantly repeat disk hostname.
Could we have everything in one place, so that it would look structured?
We can, with the WITH statement, let's define the same but in more concise way:
Code Select
DATA server {
my-precious-epyc1, 4096 WITH disks {
root-disk, 1000000000000;
},
my-precious-epyc2, 8192 WITH disks {
root-disk, 1500000000000;
},
}
And here's the magic. We can define child or foreign key elements with WITH keyword and key of parent element will travel to children. There can be many levels of children and WITH statement can also be nested arbitrarily deep. There's a bunch of logic to check for errors, you can read test suite.
But long story short, this is not the garbage of `.yaml` where you can write anything we want, then you run tests and pray it will work. All fields are checked of being appropriate type, all fields must be defined, no null values are allowed and all the stuff like that is checked. Consider this typesafety as strong as defining struct in Rust or OCaml and knowing it will never have nulls or funny values.
Also, there's another variation of `WITH` so that our elements begin to look completely like traditional nested maps in programming languages, this statement is also equivalent:
Code Select
DATA STRUCT server [
{
hostname: my-precious-epyc1, ram_mb: 4096 WITH disks {
disk_id: root-disk,
size_bytes: 1000000000000,
},
},
{
hostname: my-precious-epyc1, ram_mb: 4096 WITH disks [{
disk_id: root-disk,
size_bytes: 1500000000000,
}]
}
]
So, we represented the same data in three ways and all this will end up as columns for us to analyze.
Aight, what can we do, how about our data correctness?
We can write SQL (thanks embedded sqlite) to prove anything we want about our data with good ol' SQL.
Let's write a proof that we don't have smaller disks than 10GB.
Code Select
PROOF "no disks exist less than 10 gigabytes" NONE EXIST OF disks {
SELECT rowid
FROM disks
WHERE size_bytes < 10000000000
}
How do we prove we have nothing of certain kind? By searching for it and finding none. This is important, because if this proof in eden data language fails, it will return rowid of the offending rows which can be printed out to user so he could figure out where to fix his data.
Okay, SQL proof might be a little overkill on this, we have also column checks (thanks embedded lua).
Here's how we could have defined the disks table to have same thing checked with lua:
Code Select
TABLE disks {
disk_id TEXT PRIMARY KEY CHILD OF server,
size_bytes INT,
CHECK { size_bytes >= 10000000000 }
}
Also, lets have a lua computed column for size in megabytes of the disk:
Code Select
TABLE disks {
disk_id TEXT PRIMARY KEY CHILD OF server,
size_bytes INT,
size_mb INT GENERATED AS { size_bytes / 1000000 },
CHECK { size_bytes >= 10000000000 }
}
Lua snippet must return an integer or compiler yells at you. No nulls are ever allowed to be returned by computed columns either.
But wait, there's more!
Datalog is the most elegant query language I've ever seen my life. But for datalog to be of any practical use at all, we cannot have any queries that refer to non existing facts or rules. I've found a decent datalog implementation for rust https://crates.io/crates/asdi , unfortunately, it does not support `NOT` statements or arithmetic operators of less, more and etc. So, I'll show two datalog proofs against our data, one that works today (even though it is meaningless) and one that would be practical and would work as soon as asdi starts supporting less than operator.
Code Select
PROOF "no disks exist less than 10 gigabytes, doesn't work today" NONE EXIST OF disks DATALOG {
OUTPUT(Offender) :- t_disks__size_mb(Size, Offender), Size < 10000.
}
PROOF "just check that no disks with name 'doofus' exists, works" NONE EXIST OF disks DATALOG {
OUTPUT(Offender) :- t_disks__disk_id("doofus", Offender).
}
As you can see, our computed column size_mb is available in datalog to query.
But wait, there's more! EdenDB exports typesafe Rust or OCaml code to work with. Basically, once everything is verified we can generate typesafe code and analyze our data with a programming language if we really want to perform some super advanced analysis of our data.
Let's run this:
Code Select
edendb example.edl --rust-output-directory .
On my computer this compilation literally took 6 milliseconds (thanks rust!). It should never appear in a profiler in a compilation process, unlike most compilers these days...
Let's see the rust source that got compiled!
Code Select
// Test db content
const DB_BYTES: &[u8] = include_bytes!("edb_data.bin");
lazy_static!{
pub static ref DB: Database = Database::deserialize(DB_BYTES).unwrap();
}
// Table row pointer types
#[derive(Copy, Clone, Debug, serde::Deserialize)]
pub struct TableRowPointerServer(usize);
#[derive(Copy, Clone, Debug, serde::Deserialize)]
pub struct TableRowPointerDisks(usize);
// Table struct types
#[derive(Debug)]
pub struct TableRowServer {
pub hostname: ::std::string::String,
pub ram_mb: i64,
pub children_disks: Vec<TableRowPointerDisks>,
}
#[derive(Debug)]
pub struct TableRowDisks {
pub disk_id: ::std::string::String,
pub size_bytes: i64,
pub size_mb: i64,
pub parent: TableRowPointerServer,
}
// Table definitions
pub struct TableDefinitionServer {
rows: Vec<TableRowServer>,
c_hostname: Vec<::std::string::String>,
c_ram_mb: Vec<i64>,
c_children_disks: Vec<Vec<TableRowPointerDisks>>,
}
pub struct TableDefinitionDisks {
rows: Vec<TableRowDisks>,
c_disk_id: Vec<::std::string::String>,
c_size_bytes: Vec<i64>,
c_size_mb: Vec<i64>,
c_parent: Vec<TableRowPointerServer>,
}
// Database definition
pub struct Database {
server: TableDefinitionServer,
disks: TableDefinitionDisks,
}
// Database implementation
impl Database {
pub fn server(&self) -> &TableDefinitionServer {
&self.server
}
pub fn disks(&self) -> &TableDefinitionDisks {
&self.disks
}
pub fn deserialize(compressed: &[u8]) -> Result<Database, Box<dyn ::std::error::Error>> {
// boring deserialization stuff
...
}
}
// Table definition implementations
impl TableDefinitionServer {
pub fn len(&self) -> usize {
self.rows.len()
}
pub fn rows_iter(&self) -> impl ::std::iter::Iterator<Item = TableRowPointerServer> {
(0..self.rows.len()).map(|idx| {
TableRowPointerServer(idx)
})
}
pub fn row(&self, ptr: TableRowPointerServer) -> &TableRowServer {
&self.rows[ptr.0]
}
pub fn c_hostname(&self, ptr: TableRowPointerServer) -> &::std::string::String {
&self.c_hostname[ptr.0]
}
pub fn c_ram_mb(&self, ptr: TableRowPointerServer) -> i64 {
self.c_ram_mb[ptr.0]
}
pub fn c_children_disks(&self, ptr: TableRowPointerServer) -> &[TableRowPointerDisks] {
&self.c_children_disks[ptr.0]
}
}
impl TableDefinitionDisks {
pub fn len(&self) -> usize {
self.rows.len()
}
pub fn rows_iter(&self) -> impl ::std::iter::Iterator<Item = TableRowPointerDisks> {
(0..self.rows.len()).map(|idx| {
TableRowPointerDisks(idx)
})
}
pub fn row(&self, ptr: TableRowPointerDisks) -> &TableRowDisks {
&self.rows[ptr.0]
}
pub fn c_disk_id(&self, ptr: TableRowPointerDisks) -> &::std::string::String {
&self.c_disk_id[ptr.0]
}
pub fn c_size_bytes(&self, ptr: TableRowPointerDisks) -> i64 {
self.c_size_bytes[ptr.0]
}
pub fn c_size_mb(&self, ptr: TableRowPointerDisks) -> i64 {
self.c_size_mb[ptr.0]
}
pub fn c_parent(&self, ptr: TableRowPointerDisks) -> TableRowPointerServer {
self.c_parent[ptr.0]
}
}
To get rows from table we can only get them through TableRowPointer special type for every single table. This type is basically wrapped usize and is a zero cost abstraction in rust. But, if you were to use raw usize you'd have a chance of passing TableRowPointerDisks to the server table, which is impossible here. TableRowPointer is just an index to arrays of our column or row stored data.
There are only two ways we can get TableRowPointer for every table:
1. We do a seq scan through entire table to get valid pointers
2. Pointers to other tables may exist as a column in a table. For instance, we can get generated .parent from disk row, or children_disks column generated for server table
Database is immutable and can never be mutated. User in rust can only ever get immutable references to columns. Meaning, you can run thousands of proofs in parallel against this data without ever worrying about locks/consistency and etc. Once your database is compiled it is a done deal and it will never change.
So we don't have nasty garbage in our api like, does this row exist? I better return an Option! No, if you ever have a TableRowPointer value it will ALWAYS point to a valid row in a one and only unique table. You can clone that pointer for free, store it in million other places and it will always point to the same column in the same table.
Of course, we should prefer using column api for performance, getting entire table row is added for convenience.
Deserialization assumes certain order in the include_bytes!() binary data and does not maintain data about tables already read/etc - we just assume that we wrote things in certain order in edendb and read them back in the same order. Also, binary data for rust is compressed with lz4 compression.
OCaml api is analogous and gives the same guarantees. Immutable data, separate types for table pointers for each table and so on.
Okay, let's do something practical with this, let's prove that no intel disks are never next to some cheap crucial disks to not ever humiliate them like that!
We'll change schema a little bit, let's add, what is effectively, a disk manufacturer enum:
Code Select
TABLE disk_manufacturer {
model TEXT PRIMARY KEY,
}
DATA EXCLUSIVE disk_manufacturer {
intel;
crucial;
}
Code Select
DATA EXCLUSIVE says, that this data can be only defined once. Otherwise, we could keep filling up this enum with many statements in different places, this effectively makes this table an enum.Also, let's add our disks to contain the make column with this data:
Code Select
TABLE disks {
disk_id TEXT PRIMARY KEY CHILD OF server,
size_bytes INT,
size_mb INT GENERATED AS { size_bytes / 1000000 },
make REF disk_manufacturer,
CHECK { size_bytes >= 10000000000 }
}
Code Select
REF disk_manufacturer means this column has to refer by primary key to a single row in disk_manufacturer, you can never add invalid disk manufacturer value in the disk table or compiler yells.Now our data is redefined with disk manufacturer:
Code Select
DATA STRUCT server [
{
hostname: my-precious-epyc1, ram_mb: 4096 WITH disks {
disk_id: root-disk,
size_bytes: 1000000000000,
make: intel,
},
},
{
hostname: my-precious-epyc2, ram_mb: 8192 WITH disks [{
disk_id: root-disk,
size_bytes: 1500000000000,
make: intel,
},{
disk_id: data-disk,
size_bytes: 1200000000000,
make: crucial,
}]
}
]
So, how would the rust source look to prove that no intel disk is next to a cheap crucial disk? There ya go, full main.rs file:
Code Select
#[macro_use]
extern crate lazy_static;
#[allow(dead_code)]
mod database;
fn main() {
let db = &database::DB;
db.disks().rows_iter().filter(|i| {
// we only care about intel disks
db.disk_manufacturer().c_model(db.disks().c_make(*i)) == "intel"
}).for_each(|intel_disk| {
let parent = db.disks().c_parent(intel_disk);
let children_disks = db.server().c_children_disks(parent);
for pair in children_disks.windows(2) {
match (
db.disk_manufacturer().c_model(db.disks().c_make(pair[0])).as_str(),
db.disk_manufacturer().c_model(db.disks().c_make(pair[1])).as_str(),
) {
("intel", "crucial") | ("crucial", "intel") => {
panic!("Are you kidding me bro?")
}
_ => {}
}
}
});
}
Do you miss endless matching of some/none options to check if some value by key exists in the table or endless unwraps? Me neither. We just get all the values directly because we know they will always be valid given we have table row pointers which can only ever be valid.
Full example project can be found here
So, basically, let's recap all the high level tools EdenDB gives to be successful working and building assumptions about your data:
1. SQL proofs
2. Lua checks/computed columns
3. Datalog (so far meh)
4. Analyze data directly in Rust or OCaml if all else fails
Basically, 4 ways to analyze the same data from four different languages and all data is statically typed and super fast/column based in the end.
Also, there are these features I didn't mention:
- include multiple files syntax
- include lua files
- unique constraints
- sqlite materialized views
- countless checks for correctness (check enum count in errors.rs file)
To see all features of EdenDB check out the tests, because I usually try to test every feature thoroughly.
And more will be added as I see fit.
What can I more say? Having such foundations, time to build the most productive open source web development platform of all time 😜
#17
The pattern V2 / The pattern V2 architecture
Last post by CultLeader - August 01, 2022, 05:06:31 PMThis posts assumes you have read the main thesis and are familiar with the concept of the pattern.
Sup, after doing the pattern for some time something inevitably happened that happens in every craftsmanship.
I happed to improve upon initial designs.
So, I want to list a few pain points I had working with the pattern v1:
1. Representing abstractions as data is kind of tedious, even in high level programming language like OCaml. You need to write functions, with default arguments and stuff. Ideally, I'd see only data when I'm working with data and not be burdened by programming language concepts.
2. Proving stuff about your data is possible, but not too convenient. For instance, it is trivial to write SQL queries against data, but if you need to iterate in loops against same data doing what SQL would do becomes tedious pretty quickly.
3. Adding data is annoying. I used to have one list in ocaml with all rest endpoints, but if you need more teams, or logical splitting across files then you need to write them by hand to be merged.
What is the solution?
I inevitably came to the conclusion that there needs to be a separate data language to what I want to do where abstractions can be represented simply and trivially.
Hereby, I introduce EdenDB with its own Eden Data Language (.edl file extension) (covered in the separate post).
So, the new architecture, instead of two layers has three layers:
1. Data platform, highest level of data defined with Eden Data Language
2. Codegen layer, to generate all typesafe abstractions from our high level data language
3. The final feminine plane layer, where the user just fills in the blanks programming against typesafe interfaces
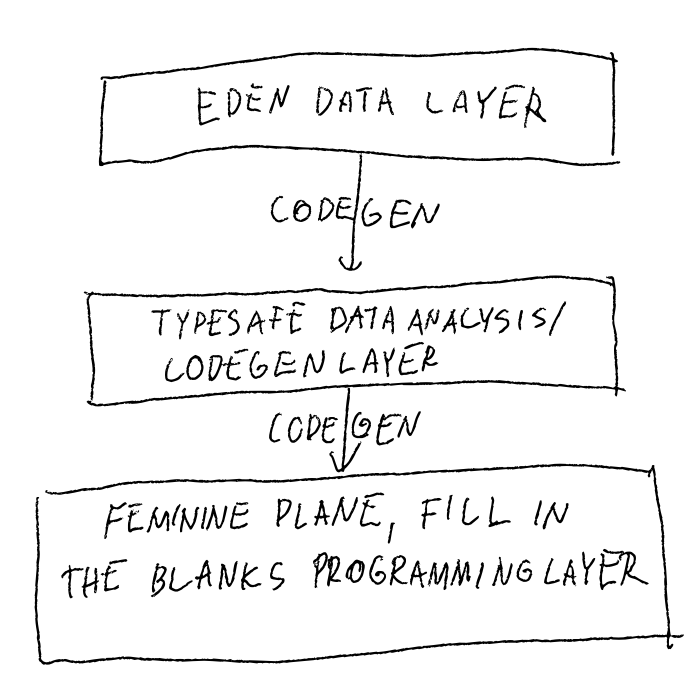
The rest of the posts in this board will be about development and implementation of the version 2 of the pattern, it will become an open source project available to everyone.
Sup, after doing the pattern for some time something inevitably happened that happens in every craftsmanship.
I happed to improve upon initial designs.
So, I want to list a few pain points I had working with the pattern v1:
1. Representing abstractions as data is kind of tedious, even in high level programming language like OCaml. You need to write functions, with default arguments and stuff. Ideally, I'd see only data when I'm working with data and not be burdened by programming language concepts.
2. Proving stuff about your data is possible, but not too convenient. For instance, it is trivial to write SQL queries against data, but if you need to iterate in loops against same data doing what SQL would do becomes tedious pretty quickly.
3. Adding data is annoying. I used to have one list in ocaml with all rest endpoints, but if you need more teams, or logical splitting across files then you need to write them by hand to be merged.
What is the solution?
I inevitably came to the conclusion that there needs to be a separate data language to what I want to do where abstractions can be represented simply and trivially.
Hereby, I introduce EdenDB with its own Eden Data Language (.edl file extension) (covered in the separate post).
So, the new architecture, instead of two layers has three layers:
1. Data platform, highest level of data defined with Eden Data Language
2. Codegen layer, to generate all typesafe abstractions from our high level data language
3. The final feminine plane layer, where the user just fills in the blanks programming against typesafe interfaces
The rest of the posts in this board will be about development and implementation of the version 2 of the pattern, it will become an open source project available to everyone.
#18
Development Tips / The winner takes it all
Last post by CultLeader - June 12, 2022, 11:03:08 AMSup bois. Let's talk about some principle which explains why democracy cannot work ever work and inevitably one platform will emerge which will be unbeatable compared to others and will get all the userbase in the entire world eventually.
Things among things cannot ever be equal as explained in the world of inequality thesis. Also, in assumptions thesis I've demonstrated that more information equals more assumptions and more assumptions equals simplicity.
From this logic flow comes inevitable conclusion that to create utter and perfect simplicity you have to have all the information. From this we reach conclusion that we must have all of our information in one place so we could use it in any way imaginable, to check any assumptions and design decisions we want in our data. This is how the pattern was born.
This is all theoretical, and makes perfect sense once you understand the pattern, but someone who hasn't tried the pattern might not see it clearly at the first. This is why I love using real world examples in my posts to connect these theoretical ideas to reality to make them easy to understand for average developer. Let's talk about systemd.
The curious case of systemd
So, in a nutshell, unix bois were using init scripts to start their background services. They look horrible, are hard to maintain and are based on shell scripts. Thankfully, I've never written init.d scripts and thanks to systemd I will never have to.
Then came some guy which said the obvious thing, which you could easily deduce independently if you know the pattern and that assumptions lead to simplicity: if we know dependencies between services we can make boot order faster than with generic sysvinit scripts which start stuff at who knows when. So, basically, systemd units define services declaratively, as data. This is still far from the power of the pattern, which encompasses all infrastructure and every service within it (similarly like Nixops does, but not dynamically typed and easier to maintain and understand).
There was a huge pushback against systemd from linux bois. And usually I couldn't care less about what linux monkeys think about anything. They cannot understand to this day why they still don't have a normally functioning desktop linux distribution that would be adopted in the mainstream and why year of linux desktop is still a dream in a soyfaggot's mind. The problem in linux monkey's mind is that they cannot conceieve value in all things working together. For them it is always "this and this small service must work independently, doesn't know anything about anything, and somehow magically integrate to the system and stuff should somehow randomly work".
Anybody who used any linux desktop for some time usually brick their system after upgrades, installing debian, yum or other packages and God forbid they try to do any funny stuff with drivers once they start working. A package is expected to be thrown in the environment it knows nothing about, it knows nothing how system is already optimized and what is done to it and it somehow needs to figure it all out how to install itself without corrupting the system, and there is no downgrade option. That's why I think in linux no distro besides NixOS, which has downgrades, latest software, reproducible builds, has any right to exist and waste everyone's time.
The monkey minds who think linux desktop is great, except when it stops working after a year or two (depending on how tech savvy you are and how much you demand from your system) made a huge pushback against systemd, which solved practical problem of spinning up services in a decent way and faster boot order with dependencies. From the standpoint of the pattern, systemd is a super tiny step towards defining everything as data, has practical benefits of practically improving everyone's life with efficiency and service management. Systemd is definitely an improvement, yet degenerate linux pagan monkeys abhorred it, without even knowing why. Like dogs without understanding that bark at any passing person.
What I want to say with this? Systemd is a super small subset of the pattern, gives a few improvements in a single system. Good that it was adopted. But the endgame is the pattern and having all of the single companies data, as services, apis, databases, typed queues defined as data.
What will happen when an open source system will emerge that will have all the abstractions software developers need defined as data in a single codebase? I only do pattern for myself and don't open source it, because I wouldn't want imbeciles filling out pull requests for 100 features, making it generic and horrible - it is now perfect for me.
But inevitably, a day will come, where there will be one open source distribution of the pattern (similarly to serverless framework, but typesafe and not javascript garbage) supporting one database, one queue management system, one monitoring framework, one logging solution, one scheduler and one underlying operating system distribution (likely NixOS and its declaration files would be used as low level assembly in the pattern solution).
The day this day comes, 90% of devops/sre yaml and spreadsheet masturbators will become useless, 99% of pre deployment logical errors (like we have to have three or five zookeepers for quorum, or this data structure upgrade is not backwards compatible) will be caught by analyzing the data in the pattern. What will happen to worthless dynamically typed languages like ruby and javascript which must have monkeys maintaining them?
Incremental thinking
I remember some talk about go, improving garbage collection latency or something like that. Some guy spake about a cycle: we make efficient hardware. Then software becomes slow. We improve software. Then hardware becomes slow. We improve hardware. And so on and so on. We don't have to be as stupid as them. All that we need to do, to make drastic improvements and to see the endgame clearly - let's have everything as data. If we have everything as data, we become a small tech god in our own limited universe and we have ultimate power with the pattern. We can restrict any service talking to anything, its cores, what interfaces it sees - simply at compile time. No need to dynamically check access - it is restricted in the language, hence more efficient. If we have all as data, 90%+ abstactions/devops/infrastructure tools no longer make sense. They are hugely complex, fighting lack of information, they do incremental improvements at best, yet they cannot holistically take all the information and use all that power to get the best possible experience.
Linux monkeys are so far behind apple, which optimized their entire m1 chip to WORK TOGETHER with their software and give the best experience that it is not even funny. MuH fReE sOfTwArE mAdE bY dIvIdEd iMbEcIlE mOnKeYs wHeRe mUh sLiDeS dOnT eVeN wOrK aT tHiS tImE.
Don't be a monkey, don't zone into the small part of the system, treat it as a low level irrelevant swappable assembly (I'll make separate post about this assembly), think holistically, of making everything work together and you'll be miles ahead of every "eVeRyThInG iS a fIlE, i hATe sYsTeMd" unix imbecile.
Things among things cannot ever be equal as explained in the world of inequality thesis. Also, in assumptions thesis I've demonstrated that more information equals more assumptions and more assumptions equals simplicity.
From this logic flow comes inevitable conclusion that to create utter and perfect simplicity you have to have all the information. From this we reach conclusion that we must have all of our information in one place so we could use it in any way imaginable, to check any assumptions and design decisions we want in our data. This is how the pattern was born.
This is all theoretical, and makes perfect sense once you understand the pattern, but someone who hasn't tried the pattern might not see it clearly at the first. This is why I love using real world examples in my posts to connect these theoretical ideas to reality to make them easy to understand for average developer. Let's talk about systemd.
The curious case of systemd
So, in a nutshell, unix bois were using init scripts to start their background services. They look horrible, are hard to maintain and are based on shell scripts. Thankfully, I've never written init.d scripts and thanks to systemd I will never have to.
Then came some guy which said the obvious thing, which you could easily deduce independently if you know the pattern and that assumptions lead to simplicity: if we know dependencies between services we can make boot order faster than with generic sysvinit scripts which start stuff at who knows when. So, basically, systemd units define services declaratively, as data. This is still far from the power of the pattern, which encompasses all infrastructure and every service within it (similarly like Nixops does, but not dynamically typed and easier to maintain and understand).
There was a huge pushback against systemd from linux bois. And usually I couldn't care less about what linux monkeys think about anything. They cannot understand to this day why they still don't have a normally functioning desktop linux distribution that would be adopted in the mainstream and why year of linux desktop is still a dream in a soyfaggot's mind. The problem in linux monkey's mind is that they cannot conceieve value in all things working together. For them it is always "this and this small service must work independently, doesn't know anything about anything, and somehow magically integrate to the system and stuff should somehow randomly work".
Anybody who used any linux desktop for some time usually brick their system after upgrades, installing debian, yum or other packages and God forbid they try to do any funny stuff with drivers once they start working. A package is expected to be thrown in the environment it knows nothing about, it knows nothing how system is already optimized and what is done to it and it somehow needs to figure it all out how to install itself without corrupting the system, and there is no downgrade option. That's why I think in linux no distro besides NixOS, which has downgrades, latest software, reproducible builds, has any right to exist and waste everyone's time.
The monkey minds who think linux desktop is great, except when it stops working after a year or two (depending on how tech savvy you are and how much you demand from your system) made a huge pushback against systemd, which solved practical problem of spinning up services in a decent way and faster boot order with dependencies. From the standpoint of the pattern, systemd is a super tiny step towards defining everything as data, has practical benefits of practically improving everyone's life with efficiency and service management. Systemd is definitely an improvement, yet degenerate linux pagan monkeys abhorred it, without even knowing why. Like dogs without understanding that bark at any passing person.
What I want to say with this? Systemd is a super small subset of the pattern, gives a few improvements in a single system. Good that it was adopted. But the endgame is the pattern and having all of the single companies data, as services, apis, databases, typed queues defined as data.
What will happen when an open source system will emerge that will have all the abstractions software developers need defined as data in a single codebase? I only do pattern for myself and don't open source it, because I wouldn't want imbeciles filling out pull requests for 100 features, making it generic and horrible - it is now perfect for me.
But inevitably, a day will come, where there will be one open source distribution of the pattern (similarly to serverless framework, but typesafe and not javascript garbage) supporting one database, one queue management system, one monitoring framework, one logging solution, one scheduler and one underlying operating system distribution (likely NixOS and its declaration files would be used as low level assembly in the pattern solution).
The day this day comes, 90% of devops/sre yaml and spreadsheet masturbators will become useless, 99% of pre deployment logical errors (like we have to have three or five zookeepers for quorum, or this data structure upgrade is not backwards compatible) will be caught by analyzing the data in the pattern. What will happen to worthless dynamically typed languages like ruby and javascript which must have monkeys maintaining them?
Incremental thinking
I remember some talk about go, improving garbage collection latency or something like that. Some guy spake about a cycle: we make efficient hardware. Then software becomes slow. We improve software. Then hardware becomes slow. We improve hardware. And so on and so on. We don't have to be as stupid as them. All that we need to do, to make drastic improvements and to see the endgame clearly - let's have everything as data. If we have everything as data, we become a small tech god in our own limited universe and we have ultimate power with the pattern. We can restrict any service talking to anything, its cores, what interfaces it sees - simply at compile time. No need to dynamically check access - it is restricted in the language, hence more efficient. If we have all as data, 90%+ abstactions/devops/infrastructure tools no longer make sense. They are hugely complex, fighting lack of information, they do incremental improvements at best, yet they cannot holistically take all the information and use all that power to get the best possible experience.
Linux monkeys are so far behind apple, which optimized their entire m1 chip to WORK TOGETHER with their software and give the best experience that it is not even funny. MuH fReE sOfTwArE mAdE bY dIvIdEd iMbEcIlE mOnKeYs wHeRe mUh sLiDeS dOnT eVeN wOrK aT tHiS tImE.
Don't be a monkey, don't zone into the small part of the system, treat it as a low level irrelevant swappable assembly (I'll make separate post about this assembly), think holistically, of making everything work together and you'll be miles ahead of every "eVeRyThInG iS a fIlE, i hATe sYsTeMd" unix imbecile.
#19
Development Tips / Broad is the way, that leadeth...
Last post by CultLeader - March 23, 2022, 09:37:41 AMEnter ye in at the strait gate: for wide is the gate, and broad is the way, that leadeth to destruction, and many there be which go in thereat: Because strait is the gate, and narrow is the way, which leadeth unto life, and few there be that find it. - Matthew 7:13-14
I, as usual, was arguing my ideas with some people. Recently I argued with a literal faggot (literal faggot).
The argument from my side is very simple and I'll repeat it 100th time - if you have your problems defined as data in one place you can analyze them any way you want and catch a lot of otherwise very hard to catch errors before production. You should always strive to represent your problems as data if you want to produce correct and working software from the get go.
And the arguments of the faggots always boil down to such things: we'll, some developer might not want to write SQL. Or, some developers prefer ruby. Or, data in database changes, statistics change or what not.
That is, they can always find some edge case, as if it is justification to throw out overall solidity of the system for one minute detail that ought to be brought down to our control eventually anyway.
Let me give you an example of what they do. For instance, Rust, as long as you write safe code you cannot have segfaults. Faggot can say "we'll, you write unsafe code and have a segfault in Rust, hence the idea of Rust is invalid!". You see what these people do? They would dismiss the entire idea of Rust because of edge case of writing unsafe code which ought to be avoided. They dismiss the idea of the pattern, which catches 90% of trivial errors before deploying something to production because of some edge case that can still sneak into 10%, which we didn't cover yet. But, given we know enough data about our domain, we could finish even that in the long run.
Let's entertain the analogy of a kings house. House of the king is clean, spotless, everyone is dressed in good clothes and everyone smells nice. Interior has very expensive furniture. Then comes some poor fellow from the street, with dirty clothes, dirty feet and smells like hell. What will the king do to such a man? To go in front of the king you need to look appropriately and follow the rules of the king's house.
The pattern, meta executable with our domain problems defined as data is the house of the king. We have certain rules. We enforce our contracts with typesafety so we wouldn't see these errors in production. We perform custom static assertions and analyses on our data. Hence why I use OCaml and Rust in our king's house. If we want to bring in the likes of Ruby in our house, this would be equivalent of bringing in the smelly, dirty bozo which takes a dump on our golden floor of our royal house. We cannot have that. How can we ensure that Ruby upholds our type signatures we set for database queries and queues if Ruby itself cannot enforce its own types? Ruby is a dirty bozo that doesn't even go into the shower to wash his clothes. Same with Python, Javascript. Why should we bring such languages into our royal house, and make our house smell like shit because dynamically typed languages cannot enforce the basic contracts, which we could generate, but which would never be enforced?
Hence, the argument - some developers are familiar with Ruby, hence we need to support it, is worthless. I could say, some bozo sleeping near the dumpster wants to drive a lamborghini. So what? The crowd of dynamically typed ruby/python/javascript faggots are not to be considered when making decisions, their votes mean nothing. If they wanted a vote in the system of the pattern, where all honourable participants of the system honour their contracts, they need to wash themselves (in javascript, for instance, they'd must use typescript), wash their clothes, humble themselves and ask admittance to the king's house.
Current software companies are like third world countries. No law, no order. Most developers are dirty, smelly bozo's. They schedule meetings about how to make two or more components work together, because typesystem is in the mind of the bozo developer and he has to remember if there will be errors (which problem you'd never have with the pattern, as compiler is thinking for you). Hence the development is slow and everyone is frustrated.
You see, it is very easy to defile yourself. A virgin girl can lose her virginity drunk to some school bad boy and become defiled for the rest of her life, whom no self respecting man will want to marry. Also, sluttery destroys morality of the nation as well (Do not prostitute thy daughter, to cause her to be a whore; lest the land fall to whoredom, and the land become full of wickedness. - Leviticus 19:29). It is very easy to spray graffiti on the wall of your house making it look like it was vandalized by irresponsible teenagers that didn't receive whooping when growing up. It is very easy to do things wrong and go out of the way and make everyone else around you to suffer. Like Jesus said, broad is the way of destruction, but narrow is the way that leadeth unto life and few will find it.
Hence, we must separate ourselves from the world and its insanity, same principle for the church and same for the software development.
Wherefore come out from among them, and be ye separate, saith the Lord, and touch not the unclean thing; and I will receive you. - 2 Corinthians 6:17
Love not the world, neither the things that are in the world. If any man love the world, the love of the Father is not in him. For all that is in the world, the lust of the flesh, and the lust of the eyes, and the pride of life, is not of the Father, but is of the world. And the world passeth away, and the lust thereof: but he that doeth the will of God abideth for ever. - 1 John 2:15-17
Here's the illustration of what I mean. There's the sea of wrong, and developer, if he wants to develop in the sea of wrong he uses services like swagger declarations of http requests and then writes them by hand in his service. He uses non typesafe rails database, writes tests, hopes it works. He uses random data format when interacting with queues - millions of places where trivial mistakes can be made.

Below, in the sea of wrong, we have our royal built house with the pattern. We have few abstractions, like typesafe interactions with postgres database, typesafe interactions with queues, typesafe calls to other REST API services. We label queries if they are mutating the database, or are readonly. We can have stress testing of certain postgres queries which will be generated since we have our queries as data. We automatically create prometheus variables for every single query we have. We store every single query ever executed against the database, with their arguments, in clickhouse table for analyzing. We have our typesafe, efficient, binary format logging system, where we could generate how those will be represented in the frontend.
In our house, there's one law, one order, one way to do things. We only allow typesafe languages in our house. We have fewer, but super solid abstractions that ALL HAVE TO WORK TOGETHER in the same ecosystem and we don't need to support hundreds of databases/queues and so on. We do not write yamls (unless generated from typesafe config). Our configurations are typesafe enums where, for instance, I don't specify a port of kafka service, I specify with enum which cluster of kafka service talks to and all ports must be defined for every cluster and are checked if they are valid, cannot clash on the same machine and so on.
To build the house of the king took time, but once it is built, you cannot imagine you were a dirty bozo once living in the street and digging dumpsters once.
Have a nice day bois.
I, as usual, was arguing my ideas with some people. Recently I argued with a literal faggot (literal faggot).
The argument from my side is very simple and I'll repeat it 100th time - if you have your problems defined as data in one place you can analyze them any way you want and catch a lot of otherwise very hard to catch errors before production. You should always strive to represent your problems as data if you want to produce correct and working software from the get go.
And the arguments of the faggots always boil down to such things: we'll, some developer might not want to write SQL. Or, some developers prefer ruby. Or, data in database changes, statistics change or what not.
That is, they can always find some edge case, as if it is justification to throw out overall solidity of the system for one minute detail that ought to be brought down to our control eventually anyway.
Let me give you an example of what they do. For instance, Rust, as long as you write safe code you cannot have segfaults. Faggot can say "we'll, you write unsafe code and have a segfault in Rust, hence the idea of Rust is invalid!". You see what these people do? They would dismiss the entire idea of Rust because of edge case of writing unsafe code which ought to be avoided. They dismiss the idea of the pattern, which catches 90% of trivial errors before deploying something to production because of some edge case that can still sneak into 10%, which we didn't cover yet. But, given we know enough data about our domain, we could finish even that in the long run.
Let's entertain the analogy of a kings house. House of the king is clean, spotless, everyone is dressed in good clothes and everyone smells nice. Interior has very expensive furniture. Then comes some poor fellow from the street, with dirty clothes, dirty feet and smells like hell. What will the king do to such a man? To go in front of the king you need to look appropriately and follow the rules of the king's house.
The pattern, meta executable with our domain problems defined as data is the house of the king. We have certain rules. We enforce our contracts with typesafety so we wouldn't see these errors in production. We perform custom static assertions and analyses on our data. Hence why I use OCaml and Rust in our king's house. If we want to bring in the likes of Ruby in our house, this would be equivalent of bringing in the smelly, dirty bozo which takes a dump on our golden floor of our royal house. We cannot have that. How can we ensure that Ruby upholds our type signatures we set for database queries and queues if Ruby itself cannot enforce its own types? Ruby is a dirty bozo that doesn't even go into the shower to wash his clothes. Same with Python, Javascript. Why should we bring such languages into our royal house, and make our house smell like shit because dynamically typed languages cannot enforce the basic contracts, which we could generate, but which would never be enforced?
Hence, the argument - some developers are familiar with Ruby, hence we need to support it, is worthless. I could say, some bozo sleeping near the dumpster wants to drive a lamborghini. So what? The crowd of dynamically typed ruby/python/javascript faggots are not to be considered when making decisions, their votes mean nothing. If they wanted a vote in the system of the pattern, where all honourable participants of the system honour their contracts, they need to wash themselves (in javascript, for instance, they'd must use typescript), wash their clothes, humble themselves and ask admittance to the king's house.
Current software companies are like third world countries. No law, no order. Most developers are dirty, smelly bozo's. They schedule meetings about how to make two or more components work together, because typesystem is in the mind of the bozo developer and he has to remember if there will be errors (which problem you'd never have with the pattern, as compiler is thinking for you). Hence the development is slow and everyone is frustrated.
You see, it is very easy to defile yourself. A virgin girl can lose her virginity drunk to some school bad boy and become defiled for the rest of her life, whom no self respecting man will want to marry. Also, sluttery destroys morality of the nation as well (Do not prostitute thy daughter, to cause her to be a whore; lest the land fall to whoredom, and the land become full of wickedness. - Leviticus 19:29). It is very easy to spray graffiti on the wall of your house making it look like it was vandalized by irresponsible teenagers that didn't receive whooping when growing up. It is very easy to do things wrong and go out of the way and make everyone else around you to suffer. Like Jesus said, broad is the way of destruction, but narrow is the way that leadeth unto life and few will find it.
Hence, we must separate ourselves from the world and its insanity, same principle for the church and same for the software development.
Wherefore come out from among them, and be ye separate, saith the Lord, and touch not the unclean thing; and I will receive you. - 2 Corinthians 6:17
Love not the world, neither the things that are in the world. If any man love the world, the love of the Father is not in him. For all that is in the world, the lust of the flesh, and the lust of the eyes, and the pride of life, is not of the Father, but is of the world. And the world passeth away, and the lust thereof: but he that doeth the will of God abideth for ever. - 1 John 2:15-17
Here's the illustration of what I mean. There's the sea of wrong, and developer, if he wants to develop in the sea of wrong he uses services like swagger declarations of http requests and then writes them by hand in his service. He uses non typesafe rails database, writes tests, hopes it works. He uses random data format when interacting with queues - millions of places where trivial mistakes can be made.
Below, in the sea of wrong, we have our royal built house with the pattern. We have few abstractions, like typesafe interactions with postgres database, typesafe interactions with queues, typesafe calls to other REST API services. We label queries if they are mutating the database, or are readonly. We can have stress testing of certain postgres queries which will be generated since we have our queries as data. We automatically create prometheus variables for every single query we have. We store every single query ever executed against the database, with their arguments, in clickhouse table for analyzing. We have our typesafe, efficient, binary format logging system, where we could generate how those will be represented in the frontend.
In our house, there's one law, one order, one way to do things. We only allow typesafe languages in our house. We have fewer, but super solid abstractions that ALL HAVE TO WORK TOGETHER in the same ecosystem and we don't need to support hundreds of databases/queues and so on. We do not write yamls (unless generated from typesafe config). Our configurations are typesafe enums where, for instance, I don't specify a port of kafka service, I specify with enum which cluster of kafka service talks to and all ports must be defined for every cluster and are checked if they are valid, cannot clash on the same machine and so on.
To build the house of the king took time, but once it is built, you cannot imagine you were a dirty bozo once living in the street and digging dumpsters once.
Have a nice day bois.
#20
Development Tips / Easiest way to attack a design...
Last post by CultLeader - January 29, 2022, 02:24:41 PM.. is by saying it is generic. And we'll cover a lot of examples that reveal these hidden inefficiencies to the naked eye.
Lets start with foundations, a CPU. x86 or ARM is a generic compute machine. Generic compute machines will never be as optimal for special tasks as dedicated ASICs. Bitcoin mining first happened on CPUs. Then, since GPU aligns more specifically with the problem of massive parallel computation people mined with GPU's. GPU's are, again a generic compute device rather made for rendering games, so the next step were creating ASIC's. Well, there's a bus stop I between GPU and ASIC I skipped called Field Programmable Gate Arrays (FPGA), but I don't know if anyone tried programming FPGA's to mine Bitcoin. Anyway, the moral of the story is that CPUs/GPUs are a generic devices that will always be beat by specialised hardware. I just spent a paragraph to say that the sky is blue, so what?
Think about a world before GPU's, FPGA's and ASIC's. It wasn't that obvious then was it? And rest assured, we will challenge a lot of de facto ideas that we will predict disintegrate in the future.
Memory allocators.
Today a lot of people spend time developing memory allocators. ME's are implementations of a generic interface of malloc and free. Think of all the possible questions you have to ask yourself when implementing malloc. Does user want a big chunk of memory or small? How often is memory freed? Does memory travel between threads? The implementors cannot have the slightest idea, because such information is not passed to the function, hence they have to make generic approximations. That is, allocators code is full of if's and else's draining precious CPU cycles trying to fight this lack of information with dynamic analysis. Dynamism is cancer too, like I mentioned in another post.
There are standard operating system allocators, then jemalloc, now mi-malloc seems to be competing for the title of the "fastest" allocator. In reality they're just better approximating to the needs of the current time real world software.
But, for instance, if a routine uses small objects we could implement a simpler small object allocator and beat the generic one. Same with big objects. Same with objects that don't need to ever be freed. Specialised allocators will always beat generic ones.
Today in Rust you pick one allocator for everything and tada... I predict that in future compilers will perform static analysis like a skilled programmer and will pick specialised allocators for routines instead of one generic allocator for everything like jemalloc, mi-malloc and so on.
So, we just murdered the today's untouchable holy cow of memory allocators and this truth will eventually become obvious in a few decades to everyone. What's next?
SQL databases. Let's pick on generic solution of query planning. What happens today is, there's dynamic table of metadata about the data in the DB. If someone makes a query the DB has to parse that statement, analyse validity with the metadata, optimise the query with table, stats and so on.
Accepting a string is a generic solution. We must spend time parsing, analysing, handling errors in our precious runtime.
How about we move information about DB tables and queries to the compile time? After all ruby monkeys write tests to be reasonably sure about DB interactions before deployment to production.
What if database tables wouldn't be binary blobs in some generic filesystem format but rather a programing language constructs?
What if your DB was a generated code of a single object where tables were hash map arrays and your planned queries are simply exposed methods that you call and have typesafe results?
What if by defining the queries you need beforehand you could eliminate all queries that don't hit indexes and never deploy that?
What if, after analysing queries for tables you would determine that multiple tables are never queried together and can be serviced by multiple cores without even needing any generic locking mechanisms?
I'd love to use such DB instead and I will probably implement one with the pattern...
Another sacred cow is dead. Let's pick on Haskell faggots!
Smug Haskell academic weenies say "everything must be pure". Guess what? Making everything pure is a generic solution. Haskell crap because of that has to copy gazillions of objects and be inefficient, this greatly complicates the development of software projects with this impractical puzzle language.
Think of Cardano, now soon to be dead shitcoin that didn't deliver anything of practical value since 2017, having four years plus of a headstart versus projects like Avalanche, Polkadot and Solana, which use practical languages like Go or Rust and already have huge ecosystems. Meanwhile ADA Haskell faggots are just beginning to optimise their 8 tps smart contract platform. Even if they do optimise and become sufficiently usable (but will never reach speeds of Rust of Polkadot and Solana) their competitors will already be huge and nobody will need yet another blockchain.
So much for imposing a generic solution of purity to your project and destroying your productivity and develoment efforts.
The more specific solution would be controlled side effects. You mark a function pure and it can only use pure functions. I imagine a programming language will emerge, or maybe provable ADA already does this, where you can query and prove the code, that it does modify variable, is pure and so on.
Third cow done. Let's get serious: Operating systems.
Think of linux and the crazy amount of generic stuff it supports. I can guarantee that there is a ton of performance left on the table because of generic linux interfaces.
For instance, Terry Davis (RIP, you genius hacker soul!) wrote temple OS which specialised in games and in his OS he could perform a million context switches versus thousands of linux. That was because he coded a specific solution and circumvented lots of wasteful abstractions that are simply not needed in his context.
So far linux seems to suffice most applications with adequate performance, but I predict more and more unikernels will appear that will function as faster databases, load balancers, search engines and so on and so on. And unikernels will also eliminate many of generic system attack vectors, such as unintended shell access.
We could go on forever and ever about things that are generic and now are costly because of that, but I don't have infinite time. Simply, if you see inefficiency, or encumberance, ask yourself, is it because, for instance, XML, JSON or YAML is generic? If something is, how could it be made specific? Maybe these could be specific, typesafe language constructs?
And you'll see angles you have never considered before.
By the way, nature seems to be created with all hardware, no generic intel chips. Specific bones, eyes, nails to every animal kind. So that speaks volumes of the infinite wisdom of our Creator!
Have a nice day
Lets start with foundations, a CPU. x86 or ARM is a generic compute machine. Generic compute machines will never be as optimal for special tasks as dedicated ASICs. Bitcoin mining first happened on CPUs. Then, since GPU aligns more specifically with the problem of massive parallel computation people mined with GPU's. GPU's are, again a generic compute device rather made for rendering games, so the next step were creating ASIC's. Well, there's a bus stop I between GPU and ASIC I skipped called Field Programmable Gate Arrays (FPGA), but I don't know if anyone tried programming FPGA's to mine Bitcoin. Anyway, the moral of the story is that CPUs/GPUs are a generic devices that will always be beat by specialised hardware. I just spent a paragraph to say that the sky is blue, so what?
Think about a world before GPU's, FPGA's and ASIC's. It wasn't that obvious then was it? And rest assured, we will challenge a lot of de facto ideas that we will predict disintegrate in the future.
Memory allocators.
Today a lot of people spend time developing memory allocators. ME's are implementations of a generic interface of malloc and free. Think of all the possible questions you have to ask yourself when implementing malloc. Does user want a big chunk of memory or small? How often is memory freed? Does memory travel between threads? The implementors cannot have the slightest idea, because such information is not passed to the function, hence they have to make generic approximations. That is, allocators code is full of if's and else's draining precious CPU cycles trying to fight this lack of information with dynamic analysis. Dynamism is cancer too, like I mentioned in another post.
There are standard operating system allocators, then jemalloc, now mi-malloc seems to be competing for the title of the "fastest" allocator. In reality they're just better approximating to the needs of the current time real world software.
But, for instance, if a routine uses small objects we could implement a simpler small object allocator and beat the generic one. Same with big objects. Same with objects that don't need to ever be freed. Specialised allocators will always beat generic ones.
Today in Rust you pick one allocator for everything and tada... I predict that in future compilers will perform static analysis like a skilled programmer and will pick specialised allocators for routines instead of one generic allocator for everything like jemalloc, mi-malloc and so on.
So, we just murdered the today's untouchable holy cow of memory allocators and this truth will eventually become obvious in a few decades to everyone. What's next?
SQL databases. Let's pick on generic solution of query planning. What happens today is, there's dynamic table of metadata about the data in the DB. If someone makes a query the DB has to parse that statement, analyse validity with the metadata, optimise the query with table, stats and so on.
Accepting a string is a generic solution. We must spend time parsing, analysing, handling errors in our precious runtime.
How about we move information about DB tables and queries to the compile time? After all ruby monkeys write tests to be reasonably sure about DB interactions before deployment to production.
What if database tables wouldn't be binary blobs in some generic filesystem format but rather a programing language constructs?
What if your DB was a generated code of a single object where tables were hash map arrays and your planned queries are simply exposed methods that you call and have typesafe results?
What if by defining the queries you need beforehand you could eliminate all queries that don't hit indexes and never deploy that?
What if, after analysing queries for tables you would determine that multiple tables are never queried together and can be serviced by multiple cores without even needing any generic locking mechanisms?
I'd love to use such DB instead and I will probably implement one with the pattern...
Another sacred cow is dead. Let's pick on Haskell faggots!
Smug Haskell academic weenies say "everything must be pure". Guess what? Making everything pure is a generic solution. Haskell crap because of that has to copy gazillions of objects and be inefficient, this greatly complicates the development of software projects with this impractical puzzle language.
Think of Cardano, now soon to be dead shitcoin that didn't deliver anything of practical value since 2017, having four years plus of a headstart versus projects like Avalanche, Polkadot and Solana, which use practical languages like Go or Rust and already have huge ecosystems. Meanwhile ADA Haskell faggots are just beginning to optimise their 8 tps smart contract platform. Even if they do optimise and become sufficiently usable (but will never reach speeds of Rust of Polkadot and Solana) their competitors will already be huge and nobody will need yet another blockchain.
So much for imposing a generic solution of purity to your project and destroying your productivity and develoment efforts.
The more specific solution would be controlled side effects. You mark a function pure and it can only use pure functions. I imagine a programming language will emerge, or maybe provable ADA already does this, where you can query and prove the code, that it does modify variable, is pure and so on.
Third cow done. Let's get serious: Operating systems.
Think of linux and the crazy amount of generic stuff it supports. I can guarantee that there is a ton of performance left on the table because of generic linux interfaces.
For instance, Terry Davis (RIP, you genius hacker soul!) wrote temple OS which specialised in games and in his OS he could perform a million context switches versus thousands of linux. That was because he coded a specific solution and circumvented lots of wasteful abstractions that are simply not needed in his context.
So far linux seems to suffice most applications with adequate performance, but I predict more and more unikernels will appear that will function as faster databases, load balancers, search engines and so on and so on. And unikernels will also eliminate many of generic system attack vectors, such as unintended shell access.
We could go on forever and ever about things that are generic and now are costly because of that, but I don't have infinite time. Simply, if you see inefficiency, or encumberance, ask yourself, is it because, for instance, XML, JSON or YAML is generic? If something is, how could it be made specific? Maybe these could be specific, typesafe language constructs?
And you'll see angles you have never considered before.
By the way, nature seems to be created with all hardware, no generic intel chips. Specific bones, eyes, nails to every animal kind. So that speaks volumes of the infinite wisdom of our Creator!
Have a nice day